从输入URL到页面加载完成的过程
参考链接
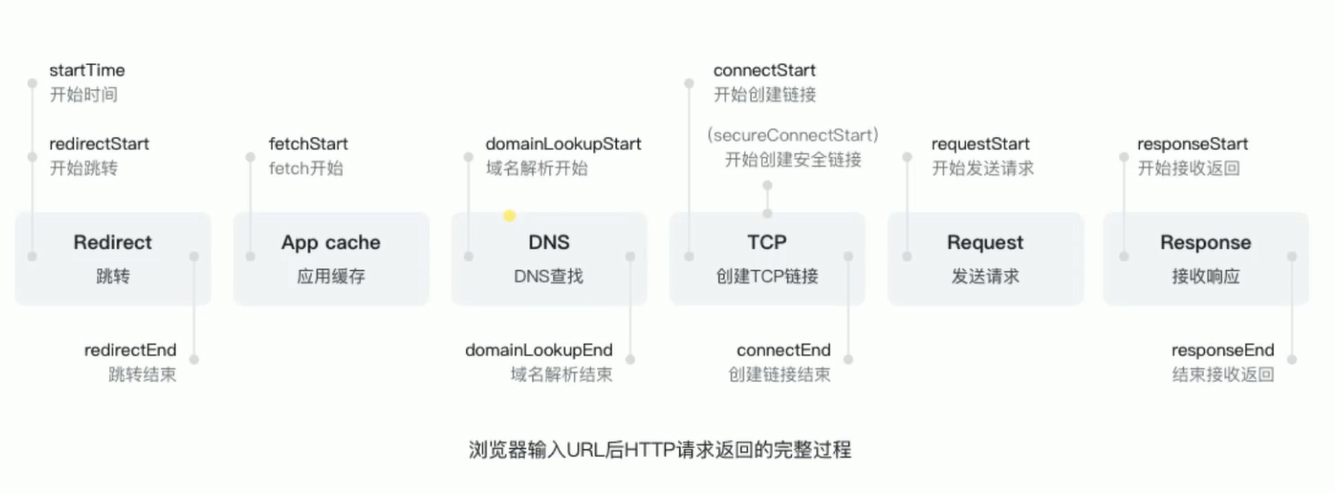
- 判断是否需要跳转(301)
- 从浏览器中读取缓存
- DNS解析
- TCP连接
- HTTP请求发出
- 服务端处理请求,HTTP响应返回
- 浏览器拿到响应数据,解析响应内内容,把解析结果展示给用户
- 在浏览器地址栏输入URL
- 判断是否有永久重定向(301)
- 如果有,直接跳转到对应URL
- 浏览器查看资源是否有强缓存,有则直接使用,如果是协商缓存则需要到服务器进行校验资源是否可用
- 检验新鲜通常有两个HTTP头进行控制
Expires和Cache-Control:
- HTTP1.0提供Expires,值为一个绝对时间表示缓存新鲜日期
- HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最大新鲜时间
- 浏览器解析URL获取协议,主机,端口,path
- 浏览器组装一个HTTP(GET)请求报文
- DNS解析,查找过程如下:
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS查询(递归查询 / 迭代查询)
- 端口建立TCP链接,三次握手如下:
- 客户端发送一个TCP的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
- TCP链接建立后发送HTTP请求
- 服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序
- 服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码
- 处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
- 服务器将响应报文通过TCP连接发送回浏览器
- 浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次挥手如下:
- 主动方发送Fin=1, Ack=Z, Seq= X报文
- 被动方发送ACK=X+1, Seq=Z报文
- 被动方发送Fin=1, ACK=X, Seq=Y报文
- 主动方发送ACK=Y, Seq=X报文
- 浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
- 如果资源可缓存,进行缓存
- 对响应进行解码(例如gzip压缩)
- 根据资源类型决定如何处理(假设资源为HTML文档)
- 解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、js文件,启动下载
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none
- 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- js解析如下:
- 浏览器创建Document对象并解析HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的文档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本**禁止使用document.write()**,它们可以访问自己script和之前的文档元素
- 当文档完成解析,document.readState变成interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readState变为complete,window触发load事件
- 显示页面(HTML解析过程中会逐步显示页面)
作者:
LARE
许可证:
CC-BY-NC-4.0